最近、Google はこれまでで最も素晴らしい機能の 1 つである、 ハミングによる曲認識をリリースしました。 Google アシスタントに「これは何の曲ですか」と尋ね、そのメロディーを口ずさむだけで、Google では慣習的に行われているように、すべて人工知能によって認識されます。
Google が自身のブログで詳しく説明したいと考えているため、Google がこれをどのように達成したかについて説明します。口ずさむメロディーから、あなたが考えていた曲の正確な検索結果まで。どうすればそれを達成できるのでしょうか?
結果を得るためにメロディーを分離する
ほとんどの音楽認識モデルは、サウンドのサンプルを取得し、それをスペクトログラム (上記のようなもの) に変換し、そのスペクトログラムをデータベース内のスペクトログラムと比較することによって機能します。ハミングの問題は、スペクトログラムにはメロディーしか含まれていないため、情報が少ないことです。
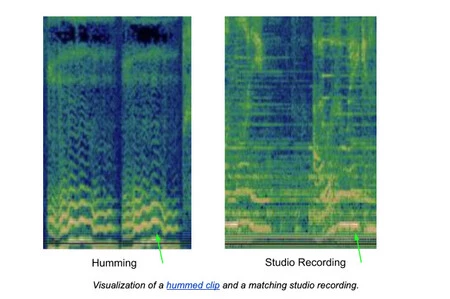
完全な仕様には、楽器、歌詞、リズム、および曲のすべての重要な要素が含まれています。 「Bella Ciao」スペクトログラムに対応する画像でわかるように、スタジオ スペクトログラムとハミング スペクトログラムの違いは非常に明らかです。このような大量の情報が直面する問題を解決するために、 Google はメロディーに焦点を当て、曲の残りの要素は重要ではありません。
専門的な話に入ることを避けるために非常に要約すると、Google には 5,000 万を超えるスペクトログラムを含むデータベースがあり、それを使用して、私たちが口ずさむ曲を、その曲の主要なメロディだけで見つけることができます。モデルは上記のメロディーのみに焦点を当てているため、バックグラウンドノイズがあっても、これらすべてが達成されます。
モデルのトレーニング
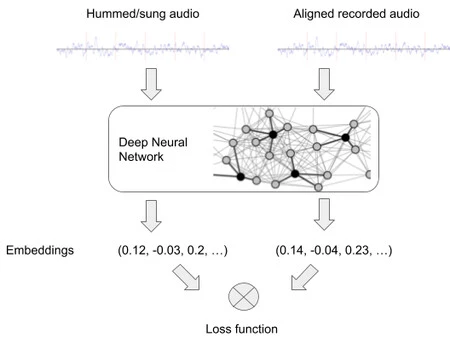
この目的を達成するために、Google は、長い間使用されてきたNow Playing および Sound Search 認識モデルに特定の変更を加えました。このトレーニングでは、彼はペア (ハミング音声と録音音声) のシステムを使用し、それぞれの異なるエンベディングを生成しました。言い換えると?
Google は、リファレンス録音と同様のハミング埋め込みを生成できるようになるまで、自社のニューラル ネットワークをこれらのペアに何百万回も公開します。このシステムを使用すると、Google は5 曲中 4 曲を認識できると主張しており、テストでは効率が非常に高いことがわかりました。
すでに述べたように、Google はオリジナルと比較するために何百万もの鼻歌を歌う必要があるため、曲のトーンを抽出できる SPICE と呼ばれるソフトウェアを使用して鼻歌をシミュレートする必要がありました。参考までに、 これがオリジナルのオーディオで、これがソフトウェアによって生成されたオーディオです。ソフトウェア出力はニューラル ネットワークを使用して洗練され、さらにクリーンになります。
この説明は、少なくともこの場合、 Google がこのシステムの作成にユーザー データを使用していないことを理解するのにも役立ちます。間違いなく、新しいハミングはネットワークのトレーニングを継続し、ネットワークをより正確にするのに役立ちますが、オリジナルの方法は彼らが示すものです。つまり、ハミングされた歌をシミュレートしてオリジナルと比較することです。