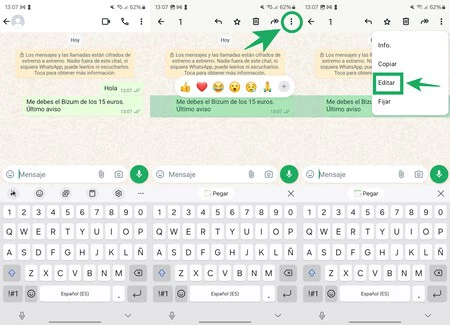
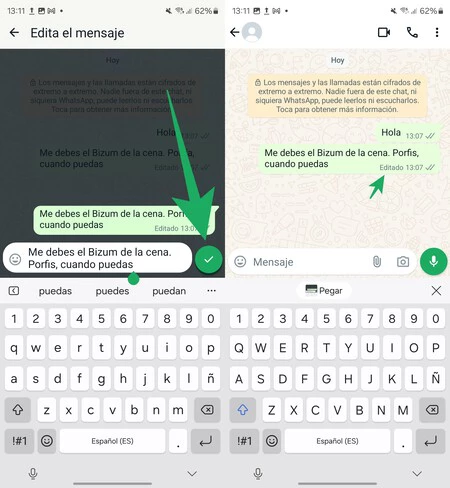
何ヶ月も待たされた後、今日、 Google I/O (Google の開発者向け年次カンファレンス) として知られるイベントが始まり、人工知能が紛れもなく主役となったイベントが開催されました。
他の多くの新機能の中でも、Google は、ユーザーの創造的なプロセスを改善することを目的としたビデオと画像用の新しい生成 AI モデルを発表して私たちを驚かせました。 I Spy、イメージ 3、ルリアとは一体何ですか?以下に詳細をすべてお伝えします。
Veo ではテキストプロンプトからビデオを作成できます
数か月前、 テキストからあらゆるタイプのビデオを作成できる素晴らしい OpenAI ツールである Sora についてお話しました (ただし、現時点では公開されていません)。今日のイベントでGoogleは、テキストプロンプトからビデオを生成できるモデルであるVeoを発表し、同社はこれでOpenAIと競合するつもりだ。
Google が述べているように、Veo は、さまざまな視覚スタイルで 1 分を超える長さの1080p 解像度のビデオを生成できます。前述したように、このツールはユーザーのテキスト指示に基づいて機能し、元のアイデアにできるだけ似たビデオを生成します。
AI によって生成されたビデオについて話すときに最も一般的な懸念の 1 つは、それらを実際のビデオと区別するのが難しいことです。この点に関連して、Google は、Veo で作成したビデオには、人間の目には認識できない透かしが表示されることを確認しました。これにより、必要に応じて、ビデオが AI で生成されたものであることを識別できるようになります。
このモデルは現在、限られたグループの VideoFX ユーザー向けに提供されています。同社は将来的に、YouTube ショートやその他の同様の製品で Veo の機能を提供する予定です。
画像 3 では、テキストから AI を使用して画像を作成できます
AIを利用したビデオ生成はさておき、Image 3は同社が開発したテキストプロンプトからの新しい画像生成モデルです。プレゼンテーション中に、Google は画像 3 で生成されたいくつかの画像を示し、達成された詳細レベルを理解することができます。
間違いなく、このモデルで私たちの注意を引いた点の 1 つは、テキストをどのようにうまく処理できるかということです。他の同様のツールとは異なり、画像 3 はテキストの断片や単一の単語をテキストに含めたい場合に非常に良い結果が得られるようです。私たちが生成する画像。
このスタイルの他のツールを使用したことがある場合は、画像にテキストの断片を含めるように AI に依頼すると、AI が文字や単語全体をスキップするのが一般的であることがわかるでしょう。
どうやら、Image 3 の強みの 1 つはテキストのレンダリングです。上の画像からわかるように、Google の AI は、プロンプトで示された要素を使用して、いかなる種類のエラーも発生せずに単語を作成できます。
Veo で作成されたビデオの場合と同様に、画像 3 では、画像の悪用を防ぐために、画像に目に見えない透かしを追加します。
Lyria は AI のサポートにより音楽制作に革命を起こすことを目指しています
昨年末、人工知能を使用して音楽の作成方法に革命を起こすという Google の計画である Lyria について初めて知りました。これを達成するために、同社はさまざまなミュージシャン、作曲家、音楽プロデューサーと合意に達し、これにより、過去数か月の間に出現した同様のツールとの差別化が可能になります。
この分野における同社の取り組みの一環として、Google は Music AI Sandbox を提供しています。これは、さまざまな楽器を使用して音楽をゼロから作成できるAI を使用した音楽ツール スイートです。
さらに、同社はこの機会を利用して、Wyclef Jean、Marc Rebillet、Justin Tranter との新たなコラボレーションを発表し、Google の人工知能モデルをどのように使用して曲を作成するかを説明し、YouTube チャンネルで実際の例を公開しました。ビデオ コンテンツと同様に、Lyria で作成された曲には、同社が使用するテクノロジであるSynthIDのおかげで目に見えないウォーターマークが表示されます。
なるほど、画像3とルリア。これは Google のビデオ、画像、音楽用の生成 AI モデルです・関連動画